Uncovering Big Data Bias in Sustainability Science
By Nick Record and Lourdes Vera
One of the most valuable resources in the world today is data. Data volume, velocity, variety, and veracity outline our notion of “big data,” and like a resource extracted from under the ground, big data is “mined” for value using artificial intelligence techniques. Sustainability sciences and practices are rooted in data—both Earth systems data and social data. Whether trying to manage sustainable fisheries or planning climate change adaptation, the move toward big data science has been a paradigm shift with a transformative effect.
Like many new technologies, big data and artificial intelligence are viewed mainly in terms of their immense potential benefit. We read stories about how these tools are detecting tumors and making learning more accessible for people with (dis)abilities. In the tech world, there is huge investment going into data aggregation, storage, and processing infrastructure—often without any idea of what the data will be used for (Raley 2013). The idea is that with enough data and computing clusters, algorithms will find patterns that conventional science cannot. By revealing these new patterns efficiently to business analysts, researchers, and decision makers, big data mining is transforming science and society. Even this article is in the big data stream, to be sucked in by web crawlers and digested by algorithms.
As is often the case, rapid deployment of technology is justified for the potential advances without due consideration of the potential pitfalls. This is why Mary Shelley’s Frankenstein (1818) should be required reading for science degrees. Big data and learning algorithms are already deeply embedded into our everyday lives, and much like with Dr. Frankenstein’s creation, we are now seeing the unintended consequences unfold before our eyes.
To understand how big data could affect sustainability science, we need to understand that data is not objective: humans not only analyze data but engineer the tools and design the research that generates it. By removing humans from a process, one might hope to remove “human error”—so the logic goes. In practice, social systems of inequality such as racism, classism, heteropatriarchy, and ableism are built into the big data landscape. By social systems, we mean the people, institutions, and relationships between them that make up society. Social systems can produce inequalities, imbalances of power influencing every aspect of our lives, including why and how data is produced.
To see how inequality is embedded in data, we can look at well-studied cases from everyday life. For example, when companies have to sort thousands of résumés for jobs, they often automate the process using résumés as a big data resource. Algorithms “learn” patterns by associating certain résumé traits with information about which employees are more successful over time. Efficient and cost-effective, the algorithm comes with the veneer of objectivity. However, the people (data points) who have been successful employees in the past are more often those who come from historically privileged groups; algorithmic audits show that a job applicant can lose points based on features like “inferred gender” (gender inferred from other data in the application; Chen et al. 2018). Essentially, inequality is unwittingly built into algorithms and the big data they manipulate so that a process once completed by humans can be automated. No dataset, no matter how extensive, is truly “raw data” (Gitelman & Jackson 2013).
Now that résumé-sorting algorithms are ubiquitous, software engineers are playing catch-up, trying to reverse engineer bias out of the system (Raub 2018). Similar big data applications are everywhere, ranging from predictive policing to parole decisions, such as when courts prosecute according to factors like education level that predict whether a defendant will commit another crime. How can “bias” be reverse-engineered when the fact that the algorithm exists is rooted in social systems of inequality? Automation, after all, helps businesses generate more revenue while cutting down on employment and pushes defendants through a broken criminal justice system. With any big data resource, “even the initial collection of data already involves intentions, assumptions, and choices that amount to a kind of pre-processing” (Rosenberg 2013). This preprocessing is magnified by learning algorithms.
In sustainability sciences, where big data and machine learning are quickly becoming standard tools, little is known about how bias and inequality will propagate through to the output. We are pulling in data from satellites, buoys, drifters, weather stations, a wide range of autonomous sensors, fishing logs, and even social media sites, to plug into our algorithms. These data sources are all conceived with certain intentions, assumptions, and choices. Because Earth systems have many interconnected components, we don’t yet know how these biases play out in terms of sustainability. Sustainability is one of the most pressing issues of our time, and we should be asking: where are the hidden biases in our data, and what are their implications?
We can begin by asking what motivates environmental data collection. One aspect of Earth systems data that has potential to introduce bias is that data can be expensive to collect. That tends to mean that access to money drives when and where data collection happens. Even the recent trend in “citizen science” projects often favors participants with access to resources and, of course, access to scientists. The data that winds up being collected often reflects the priorities of those groups. It is in some ways a capital-driven model.
To see a local example of how this might play out, we examined fisheries in the state of Maine. The links between data collection, research, and fishery sustainability are certainly complex, but a simplified way to view the connections is to compare the dollar value of a fishery to the amount of research that has been conducted on that fishery (Figure 1). By looking at the maximum annual dollar value, we have an index of potential motivation for collecting and analyzing data. The amount of research conducted, as papers published, while not a measure of data directly, gives a proxy for how much scientific effort has gone toward understanding that fishery, including surveys, experiments, analysis, etc. While this only shows a first-cut picture, the pattern that emerges has a clear signal: there is a lot more published research on the most monetarily valuable species than there is on the least monetarily valuable species.
In a way, it makes sense—we should be putting more resources toward understanding the parts of the ecosystem that feed us. There is a certain logic to that. But it also means that as we endeavor to understand how the Gulf of Maine ecosystem works, we are doing so through the lens of extraction. Our data is biased toward understanding and sustaining a narrow slice of a complex ecosystem at the expense of the biological diversity that supports it. And as biases in big data are magnified, sustainability is increasingly focused on an ever-narrower slice of the ecosystem. It is easy to find scientifically backed narratives about the sustainability of the hugely valuable lobster fishery (Wilson et al. 2007, Pershing et al. 2018, Goode et al. 2019), but where is that narrative for bloodworms?
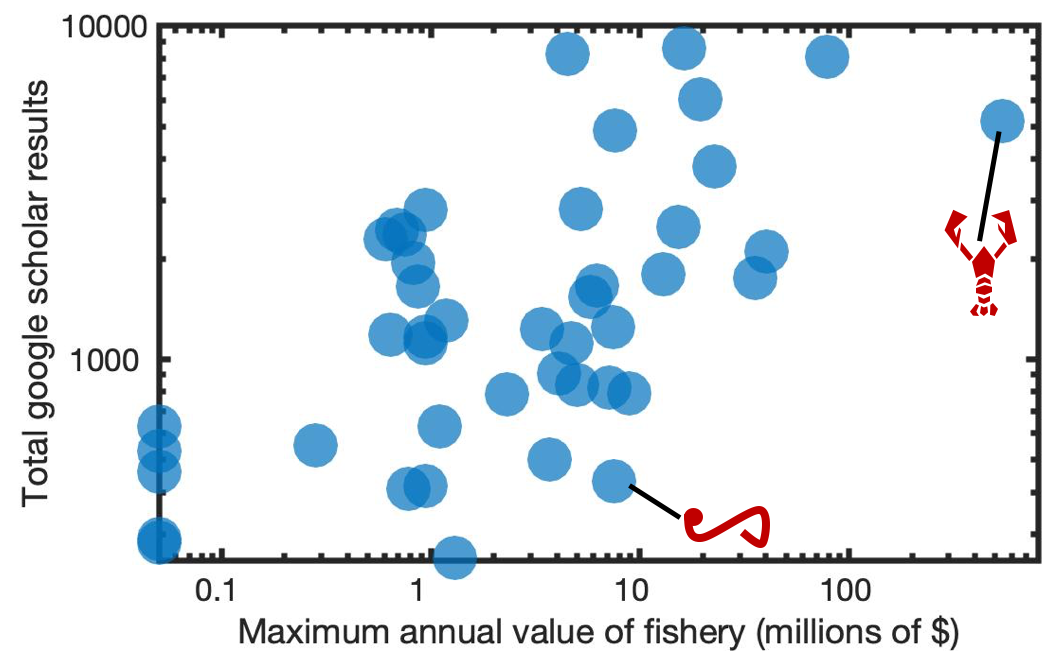
The points on Figure 1 tell more stories than just the overarching trend. The species with the most research—Atlantic cod—is only the seventh most monetarily valuable according to these metrics. However, this species was valuable on a historic scale until it collapsed around the end of the twentieth century. In addition to the time dynamic, there are many other caveats one could consider. The data are, after all, mined from other sources and aggregated for other purposes. Still, they reflect a pattern that shows up in global data: it’s not the most productive or the keystone fish species that are associated with the highest research output but instead a few highly valuable fish species (Aksnes & Browman 2016). There has long been a recognition that sustainable fisheries management should be founded on ecosystem science (Frid et al. 2006). Ecosystems have stabilizing characteristics like resilience and resistance and can dampen the boom-and-bust population swings of single species. But if our data collection, experimentation, monitoring, and analyses are driven so heavily by fisheries’ monetary value, we might benefit a limited number of fisheries, for a limited length of time, but we also stand to miss out on the holistic understanding that we need to sustain the ecosystem for the long haul.
The influence of big data biases extends well beyond fisheries. Climate change is possibly the most fundamental challenge to sustainability at present. Decisions are being made about mitigation and adaptation, and those decisions are based on data that can span either broad or very narrow swaths of society and the environment. For example, early warning services, which can reduce damage from climate-related events like storms or heat waves by around 30%, rely heavily on on-the-ground observational data, for which there are substantial gaps in developing countries. Building resilience tools like early warning systems from data like this will help, but also preferentially advantage, those places where there is advanced data infrastructure.
Another way to ask the question about biases in big data is: how does the use of particular data magnify power imbalances? Answering this question is more than just a statistical puzzle, and it involves more work than the simplified Google search of fisheries research shown here. Bias is a property of any data. The datasets we draw from to answer sustainability questions are extremely diverse, collected for a range of different purposes and motivations, and show us a range of points of view. As we pull all of these datasets together, and apply algorithms to them, there is a risk of magnifying the biases that underlie the data. The emerging field of Environmental Data Justice gives a framework for starting to address questions of data bias and power imbalances (Vera et al. 2019). The question fundamentally requires an approach that integrates natural and social sciences with a rigorous quantitative underpinning. It’s an important step if we hope to avoid the unintended consequences of hidden data bias that have befallen so many other applications.
References
Aksnes DW, Browman HI. An overview of global research effort in fisheries science. ICES Journal of Marine Science. 2016 Mar 1;73(4):1004-11.
Chen L, Ma R, Hannák A, Wilson C. Investigating the impact of gender on rank in resume search engines. InProceedings of the 2018 chi conference on human factors in computing systems 2018: 1-14.
Frid CL, Paramor OA, Scott CL. Ecosystem-based management of fisheries: is science limiting?. ICES Journal of Marine Science. 2006 Jan 1;63(9):1567-72.
Gitelman L, Jackson V. Introduction. In: Gitelman L, editor. Raw data is an oxymoron. MIT press; 2013:1-14.
Goode AG, Brady DC, Steneck RS, Wahle RA. The brighter side of climate change: How local oceanography amplified a lobster boom in the Gulf of Maine. Global change biology. 2019, 25(11):3906-17.
Pershing AJ, Mills KE, Dayton AM, Franklin BS, Kennedy BT. Evidence for adaptation from the 2016 marine heatwave in the Northwest Atlantic Ocean. Oceanography. 2018, 31(2):152-61.
Raub M. Bots, bias and big data: artificial intelligence, algorithmic bias and disparate impact liability in hiring practices. Ark. L. Rev.. 2018;71-529.
Raley R. Dataveillance and countervailance. In: Gitelman L, editor. Raw data is an oxymoron. MIT press; 2013: 121-145.
Rosenberg D. Data before the fact. In: Gitelman L, editor. Raw data is an oxymoron. MIT press; 2013: 15-40.
Shelley MW. Frankenstein, or, the Modern Prometheus : the 1818 Text. Oxford ; New York : Oxford University Press, 1998.
Vera LA, Walker D, Murphy M, Mansfield B, Siad LM, Ogden J, EDGI. When data justice and environmental justice meet: formulating a response to extractive logic through environmental data justice. Information, Communication & Society. 2019 Jun 7;22(7):1012-28.
Wilson J, Yan L, Wilson C. The precursors of governance in the Maine lobster fishery. Proceedings of the National Academy of Sciences. 2007 Sep 25;104(39):15212-7.
About the Authors
Nick Record is a Senior Research Scientist at Bigelow Laboratory for Ocean Sciences. He is an oceanographer and data scientist and directs the Center for Ocean Forecasting. Lourdes Vera is a PhD Candidate at Northeastern University in the Department of Sociology and Anthropology. She is also on the coordinating committee and co-coordinates the Environmental Enforcement Watch project with the Environmental Data and Governance Initiative.